Scaling customer support is not just about hiring more agents. The teams that scale well build a lean execution layer, automate repetitive volume, and assign clear ownership before expanding headcount.
Scaling a support team sounds like a good problem to have:
The trouble is that most teams treat hiring as the be-all and end-all for solving problems in support.
We have worked with hundreds of support organizations across industries, and the pattern is consistent. The teams that scaled badly did not fail for lack of budget or tools. They failed because they made three structural mistakes in a predictable sequence: hired too quickly, then layered management over an unstable execution layer, then let accountability for outcomes dissolve into "shared ownership" that served no one.
The teams that scaled well did the opposite. They kept the execution layer lean and productive first. They used AI agents to absorb volume before headcount pressure built. They assigned metric ownership as they meant it. This article breaks down both paths by talking about:
In our experience, there are three common failure modes people face as they scale support.
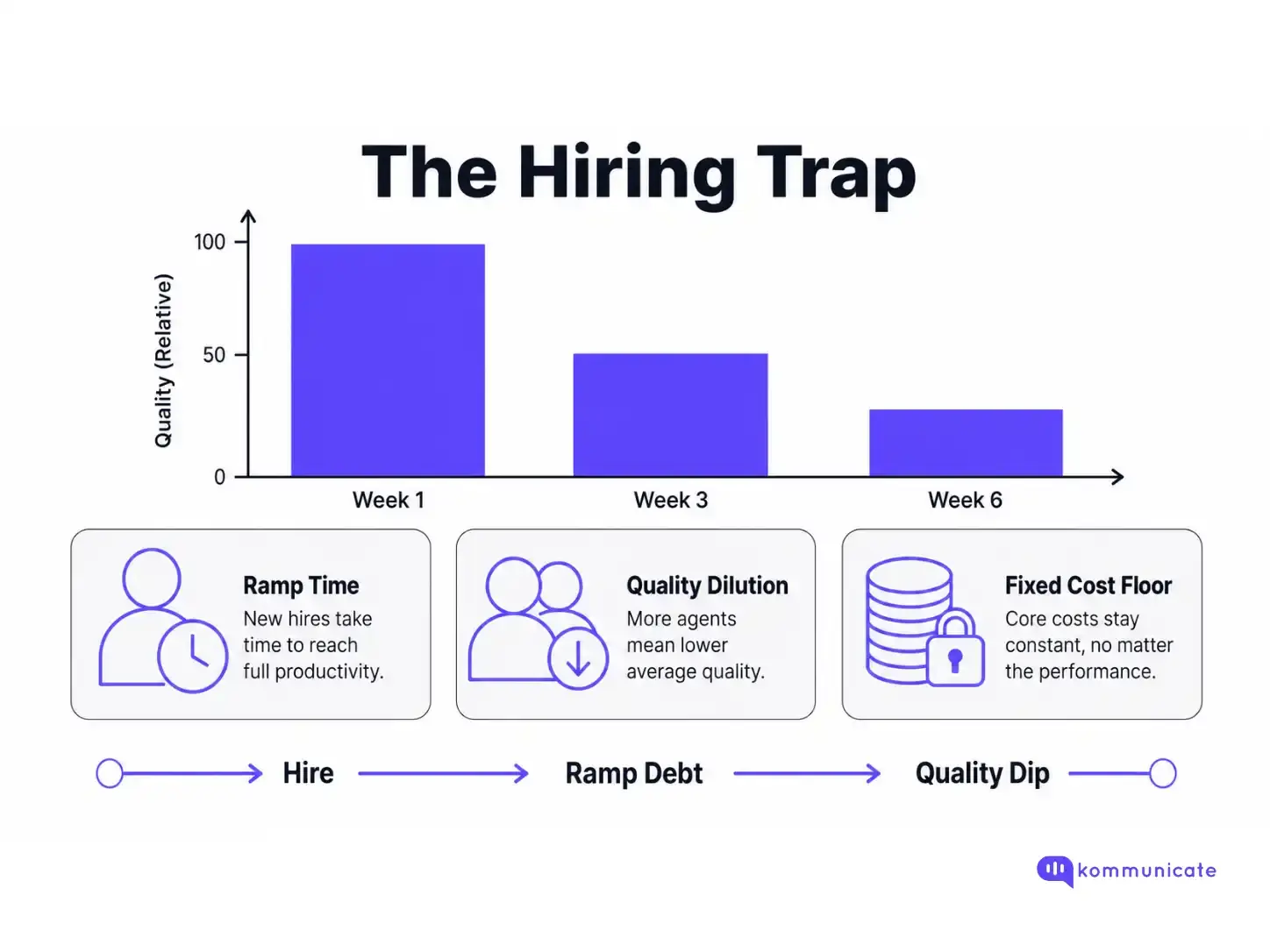
Whenever volumes rise, a lot of teams start relying on hiring to solve the issue.
However, every new agent needs:
This compounds the slowdown that you were already experiencing. Plus, headcount is stickier than volume. If growth levels off, the pressure to justify the capacity produces lower-quality benchmarks.
The teams that get this right deliberately hire late. They use AI agents to absorb the L1 volume that would otherwise trigger the hire, and only bring on agents when the ramp can be properly supported.
The hybrid path is not complicated. It just requires tolerating a queue that looks uncomfortably full for longer than feels right.
The second mistake follows naturally from the first. When you hire a cohort of agents, someone needs to manage them. So you promote your best agents into team lead roles, or hire experienced leads from outside, before your execution layer is stable.
The result is an inverted org. Four people with "lead" or "manager" in their title are overseeing six agents. The managers end up either doing IC work themselves (the good case) or operating as an approval buffer above agents who are still not at full capacity (the bad case).
Neither is what a manager should be doing at this stage. Managers should be focused on coaching, quality review, and process design. If they are answering tickets or approving every refund exception, they are plugging gaps.
The ratio problem is correctable, but it requires honesty about where your team actually is. A useful diagnostic: if your managers' calendars are more than 40% queue or ticket work, your execution layer is not ready to support the management layer sitting above it.
The fix is not to demote anyone. It is to grow the execution layer to the point where the management layer has enough individual contributors to manage, rather than stepping in to cover.
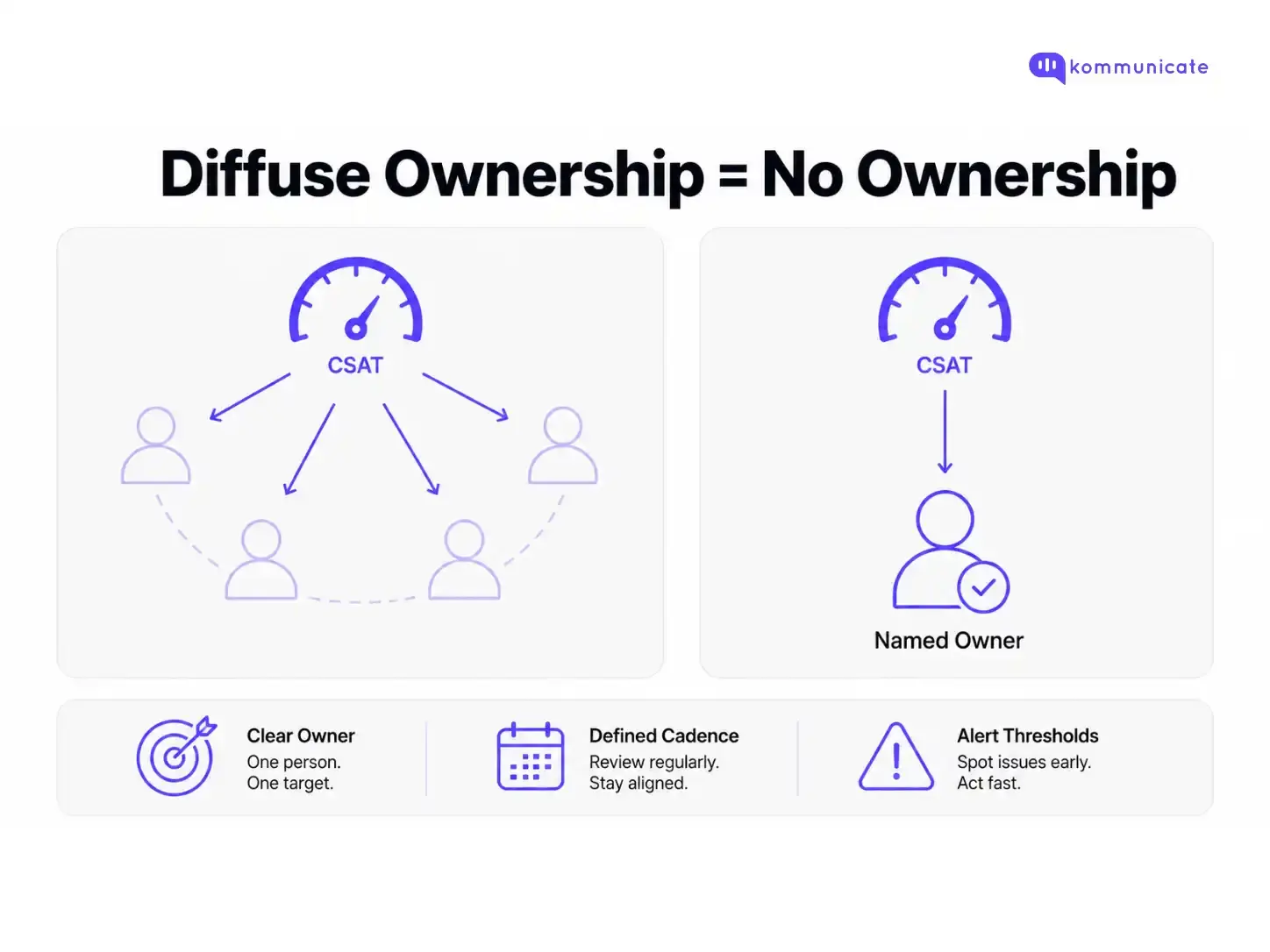
At five agents, the support manager touches almost every conversation. At thirty agents, the data is the only visibility layer, and if nobody owns the data, nobody owns the outcomes.
CSAT is a useful example. It measures interaction quality at the agent level. It should have:
What it should not be is a company-wide health metric everyone watches, but nobody can improve, which is what happens when it gets confused with NPS. For a framework on separating which metric belongs to whom, our guide to CSAT, NPS, and CES covers this in detail.
The standard to hold: every metric on your support dashboard should have a single named owner, a defined review cadence, and a threshold that triggers action.
The patterns are not complicated in retrospect, even if they require discipline to hold in the moment.
Additionally, the successful teams also leverage automation to make their ticket queues more efficient.
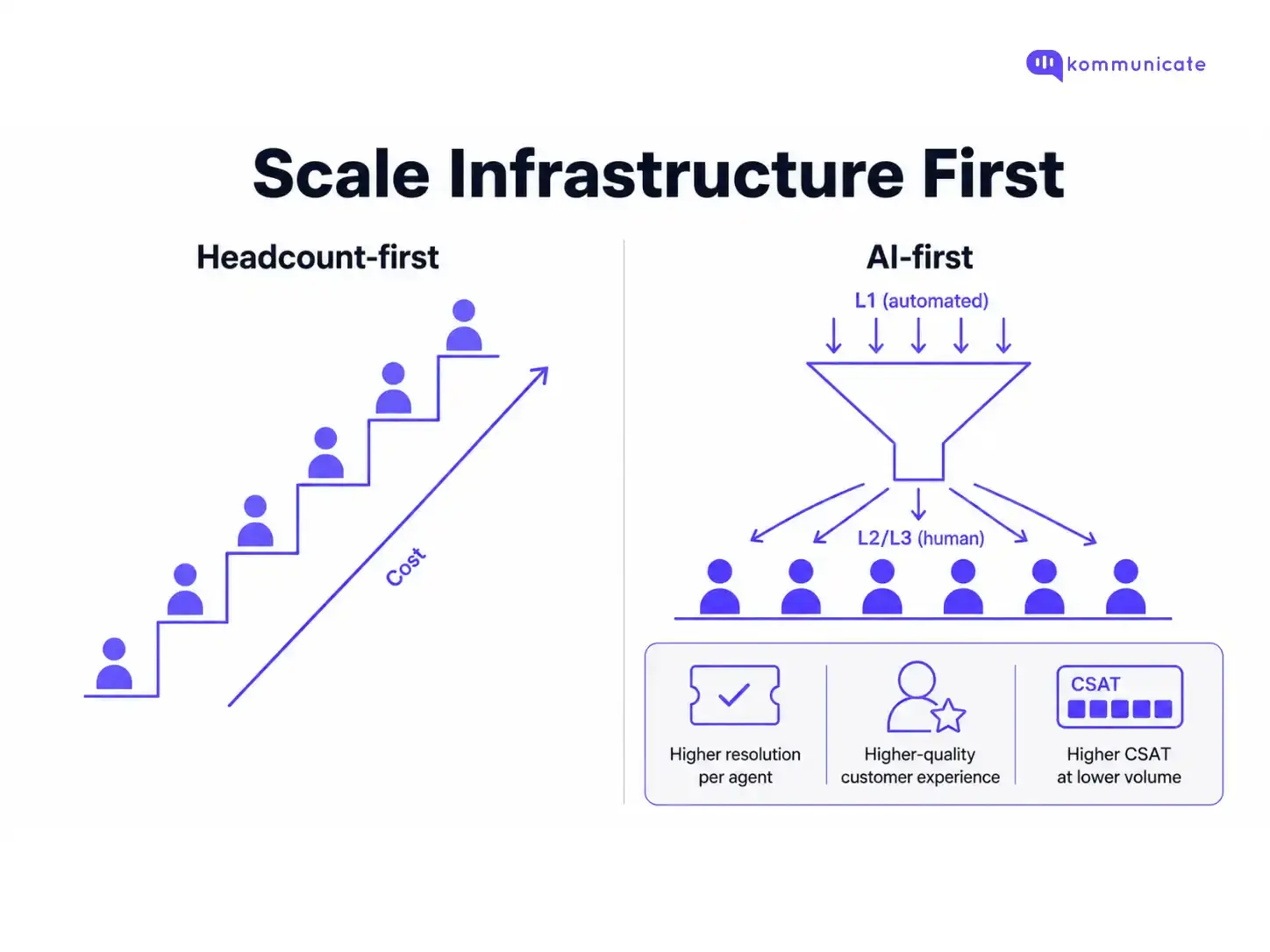
The lever most teams underuse before hitting headcount pressure is automation coverage. Specifically, AI agents handling L1 volume before that volume justifies a new hire.
If 40 to 60% of your incoming volume is:
An AI agent that resolves these tickets can change the calculus.
The teams that figured this out early hire fewer agents at each growth stage and maintain higher per-agent CSAT, because their human agents spend most of their time on interactions that actually require judgment.
The ones who hire first and automate later spend months with agents doing rote work, have low job satisfaction, and have higher attrition.
Deployment does not need to be all-or-nothing. We recommend the following strategy:
Measure containment rate and CSAT on AI-resolved conversations. Expand based on results. For a detailed look at how AI agents are reshaping support operations, the Kommunicate guide to AI in customer service covers the operational model in depth.
We have also built a Team Structure Builder below to help you assess your current org shape. Enter your agent count, ticket volume, and automation rate, and it will tell you whether your structure is healthy or top-heavy before you scale further.
Scaling customer support is a structural problem that most teams treat as a resourcing problem. The teams that got it right did not have better tools or bigger budgets.
They had a clearer sequence:
The teams that struggled reversed that sequence, and spent the next several quarters paying off the debt.
You don’t need to bet your entire support operation on AI.
Start with the conversations that are safe to automate using an AI agent.
Expand as confidence grows.
.svg)
.svg)
.svg)