Updated on February 12, 2025

When the NVIDIA stock drops by 15% and the global value of $1 trillion is lost in a day, you must sit up and take notice. On Monday, 28th Jan 2025, the launch of Deepseek R1 prompted the US markets to sell NVIDIA stocks en masse.
A Chinese company has beaten the US embargo on GPUs to create a foundational AI model that could reason (just like o1). It had done with around $5.58 million, a fraction of the cost for ChatGPT, and had wholly open-sourced the result for use.
Deepseek is a 200-person AI company built by the AI enthusiast Liang WenFeng. The company is private and funded by Liang’s other company, the AI-based Hedge Fund High Flyers.
Now, a lot of ink has already been spilled about the geopolitical implications of Deepseek, how it threatens OpenAI, and how it affects NVIDIA. So, we won’t focus on those aspects in this article. We’re covering the fascinating technology that helped a Chinese company craft a foundational model at a fraction of the cost, and we’ll cover:
1. Behind the Curtain – The Secret of Deepseek
2. Reinforcement Learning for Deepseek R1 with GRPO
3. Knowledge Transfer – Distilling Reasoning in Smaller Models
4. Optimizing Training and Inference Performance
5. Deepseek R1 v/s Open AI o1 v/s Claude Sonnet
6. Implications for Customer Service
7. Conclusion
Behind the Curtain – The Secret of Deepseek
On December 26th, 2024, Deepseek released Deepseek v3, a frontier-level AI model that could match the performance of ChatGPT 4-o. The model’s performance was eye-catching, but even AI experts were surprised by its optimized budget.
Deepseek had trained v3 on a “ridiculous budget” of $6M, and as Andrej Karpathy, an AI expert and the former Head of AI at Tesla, said, “DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs; the ones being brought up today are more around 100K GPUs. For example, Llama 3 405B used 30.8M GPU hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU hours (~11X less compute). If the model also passes vibe checks (e.g., LLM arena rankings are ongoing, and my few quick tests went well so far), it will be a highly impressive display of research and engineering under resource constraints.”
Deepseek R1 pushes this paradigm further, creating a reasoning model that can work with the chain of thought and match Open AI o1 in performance. They did this by optimizing three specific processes –
1. Reinforcement Learning (RL) – Reinforcement Learning (RL) allows a model to learn independently. In this process, a second model chooses one answer from the LLM and modifies the LLM’s weights to give similar responses in the future. For example, AlphaGo, the Google AI that beat international-level Go players, was trained to play Go matches until it learned all the moves and how to beat them. Deepseek, in particular, enhanced LLM-based RL with a new GRPO algorithm (Group Relative Policy Optimization).
2. Knowledge Transfer – Deepseek researchers have demonstrated that they can transfer the reasoning capabilities of a larger model (like Deepseek) to a smaller one. This “data-generated distillation” process makes it easier for SLMs to perform better.
3. Memory Optimization – The team optimized GPU usage by using a novel training algorithm (Dualpipe) and optimizing the training performance of their GPUs. They also reduced the amount of memory each unit GPU had to handle using the FP8 data type. These led to a far more efficient training process and a breakthrough in scaling.
These three novel discoveries and algorithmic optimizations make Deepseek R1 one of the best available models. Let’s understand each of these optimizations in some detail.
Reinforcement Learning for Deepseek R1 with GRPO
Open AI debuted the PPO algorithm in 2017. It introduced a critical model that constantly updates the weights of the base LLM to improve its outputs.
LLMs follow an internal logic to function; the model’s weights determine this logic. With PPO, the critic model (another specially trained AI model) checks the answers of the large language model and then decides if that answer is correct. If it is, it will preserve the model’s weight (reward); otherwise, the weight will be slightly changed.
GRPO doesn’t use the rankings by a learned neural network to judge the LLM’s answers. It asks the LLM to generate a group of answers. From these answers, it tries to determine a baseline and rewards the best answer in the group. This means that the best answers are prioritized.
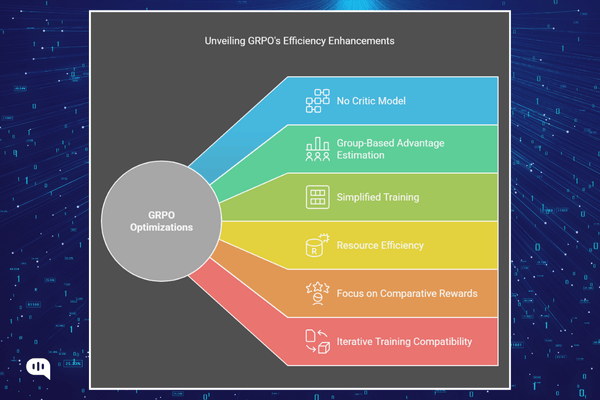
Here are the optimizations that GRPO makes over Deepseek R1:
- No Critic Model: GRPO eliminates the separate critic model used in PPO, reducing memory and computational costs.
- Group-Based Advantage Estimation: GRPO calculates advantages by comparing rewards within a group of sampled outputs for the same question instead of using a value function.
- Simplified Training: GRPO avoids complex value function training and uses average group rewards as a baseline.
- Resource Efficiency: By removing the critic and leveraging group comparisons, GRPO is more memory-efficient and scalable.
- Focus on Comparative Rewards: GRPO aligns with reward models trained on comparative data, emphasizing relative performance within groups.
- Iterative Training Compatibility: GRPO supports iterative updates with real-time policy sampling, improving stability and performance over time.
GRPO is a clever modification of PPO that aims for efficiency and effectiveness by:
- Removing the complex critic model
- Group-based, relative set evaluation techniques and a simple rule-based system were used to evaluate LLM answers.
- Performs direct parameter optimization using generated output scores
These changes make it better suited for training large models where computational overhead and resource utilization are significant concerns while improving performance.
While training Deepseek R1, the researchers rewarded the LLM for generating the correct chain of thoughts. So, if the model’s reasoning was sound, it was rewarded, even if the answers were incorrect.
This made the model give accurate results in a lot of cases. There was also emergent behavior where the model would change their reasoning logic midway through solving a particular problem.
This performance becomes even more critical when you understand that the GRPO learning in Deepseek R1 can be distilled into smaller models.

Knowledge Transfer – Distilling Reasoning in Smaller Models
Sure, Deepseek might have the GPU clusters to power the training of 7-billion parameter models. However, most open-source researchers and academics don’t have access to these resources.
So, the Deepseek R1 pioneers a model of distillation as well. Where the model’s learning and capabilities can be distilled into another model for better use.
This happens in two steps:
1. The first key step in knowledge distillation is creating training data for the smaller LLM. To do so, they use DeepSeek-R1 to generate 800k responses, using a prompt dataset to create Deepseek R1 models.
The Deepseek R1 model uses these unique methods to create responses with very high quality and chain of thought. (As its architecture/parameters that can find a good response structure/pattern).
2. The second step is to take the smaller open-source base models (Qwen or Llama) and then retrain using the 800k datasets generated by Deepseek R1, which acts like a “very high-quality teacher.”
The “Student Model” (Qwen/Llama Models) learns from the data set, which helps it find the action patterns to follow when they are facing specific prompts/problems.
This process, called Supervised finetuning (SFT), is faster and more straightforward than the training of R1.
It does not use RL but copies what R1 did in its generated datasets (where R1 learned using RL).
People have already hypothesized that Deepseek was trained on output from GPT 4-o. Hiedy Khlaaf, the Chief AI Scientist at the nonprofit AI Now Institute, says, “Even with internet data now brimming with AI outputs, other models that would accidentally train on ChatGPT or GPT-4 outputs would not necessarily demonstrate outputs reminiscent of OpenAI customized messages.”
But, even if Deepseek R1 takes PPO data from ChatGPT 4-o responses, it still re-creates the reasoning paradigm without any details from Open AI. It also trained the models v3 and R1 on tiny GPU clusters by optimizing inference and training performance.
Optimizing Training and Inference Performance
Remember the Karpathy quote. One of the key differences between Deepseek and Open AI is that the former uses a small fraction of the latter’s budget to create equivalent models.
This happens because of several steps they took during training:
DeepSeek’s Smart Model Design

1. Mixture-of-Experts Models – Deepseek uses a Mixture-of-Experts model where single parts of the model are used to answer a specific type of question. So, to optimize for a particular kind of answer, they would have to fine-tune a small part of the model instead of fine-tuning the entire model at once.
2. Multi-head Latent Attention – This unique architecture helps the LLM achieve faster training. Here, low-rank values are compressed, full values are compressed for faster calculations and then reconstituted for the results, and the focus remains on the specific output.
3. Multi-Token Prediction – Instead of just predicting the next token in a sequence, Deepseek predicts multiple tokens at once. This helps it optimize faster with more context.
Faster Data Processing
1. FP8 Mixed Precision – FP-8 is an 8-point floating point binary format that optimizes data processing. These occupy less memory while maintaining accuracy during calculations (remember that most AI training happens in a series of complex matrix multiplications). Since memory usage is low, processing is much faster.
2. New DualPipe Architecture – Deepseek worked to change the way data processing happened in their GPU units. They parallelized the data transfer and calculation processes (while transferring much smaller data sets for each iteration). Additionally, they optimized GPU processes so that each GPU was used optimally.
Efficient Data Transfer
1. Data Routing – Data transfer was optimized to transfer only the necessary data. Relevant transfer paths were also optimized so parameters don’t need to be broadcasted.
2. Communication & Computation Parallelized – All forward and backward processes on GPUs were optimized to reduce idle times for the GPU cluster.
These optimizations give Deepseek R1 some advantages
Key Results of Optimizations
1. Reduced Training Time: -DeepSeek-V3 trains faster (3.7 days per trillion tokens) than other models.
2. Lower Costs: A cheaper training process with lower energy consumption, making it eco-friendly.
3. Better Parameter Optimization: More efficient and granular optimization leads to better model performance.
4. Scalability: Designed to scale better than traditional methods, distributing tasks to reduce compute load.
These three optimizations give a massive head-start to Deepseek R1, as is apparent in its performance against o1 and Claude New Sonnet 3.5.
Reduce response time, enhance support workflows, and improve customer satisfaction with AI-driven email ticketing from Kommunicate!Deepseek R1 v/s Open AI o1 v/s Claude Sonnet
Deepseek R1 outperforms o1 and Claude Sonnet despite being the smaller model. This showcases that smaller models can be just as powerful as larger ones.
Additionally, it shows that frontier AI research isn’t limited to multi-billion dollar entities.
So, let’s understand the results:
| Feature | DeepSeek-R1 | OpenAI’s o1-1217 | Claude-Sonnet |
| Reasoning Focus | Excels in math and coding with complex logical thinking and an extended context. | Well-rounded reasoning and good general and logical reasoning skills with coding. | Strong in general knowledge with reasoning but not math or logic, and with “constitutional training emphasis” on ethics |
| Availability | Open-Source (models, data, code) | Closed-Source (API access only) | Closed-Source (API access only) |
| Performance (AIME) | 79.8% Pass@1. (86.7% with majority voting) | 79.2% pass @ 1 | Lower than R1 and 01. (not specified exactly) |
| Performance (MATH-500) | 97.3% | 96.4% | Lower than R1 and 01 (not specified exactly) |
| Flexibility | It is less flexible, as it is trained for complex reasoning. And is hyperparameter-sensitive | More general and versatile | It is more general and safer but at the cost of the performance of some specialized areas |
| Model size | Relatively more minor (7B), but models trained with the Deepseek dataset can scale up to 70B | Large (Parameter size not specified) | Large (Parameter size not specified) |
DeepSeek-R1 is a novel and robust model for complex reasoning, especially in math and coding. It demonstrates that high performance can be achieved through innovative RL training strategies and well-constructed training datasets while making it accessible to the community.
And because it is a low-cost open-source model capable of reasoning, it provides many opportunities for customer service.

How Will Deepseek R1 be Used in Customer Service?
One of the key advantages of Deepseek is that it can influence so many other models. Plus, it is open-source, so enterprises can incorporate AI into their business without worrying about data security.
It can be run locally and on-premise, even in low-memory instances, improving the adoption of AI across customer service. This will specifically happen around the following axes:
1. Costs – Deepseek R1 is 30x cheaper than o1. This means that most people can use this model for their business without incurring high costs. It also reduces the computational power needed to run an AI model, making the process more straightforward.
2. Scale – Unlike o1, using different instances of Deepseek R1 as AI agents for other tasks is cheaper. So, if you want to build an agentic system, your costs go down, and the scalability increases immediately.
3. Opportunity for Unique Models – With the distillation feature, the features of the R1 model can be used to train other smaller models. This should improve the latency of the performance of any business’s AI models.
See, the key opportunity for Deepseek lies in cost optimization. Once you remove the cost and compute barriers to AI, you can incorporate it at a much larger scale. It’s now economical to train specific AI models for using different departments in your organization. In fact, with the proper laptops and workstations, an enterprise business can create a unique AI assistant for each of its customer service agents.
Parting Thoughts
DeepSeek R1 demonstrates that AI innovation isn’t exclusive to tech giants with massive budgets. Through advanced techniques like GRPO and FP8 precision, they created powerful AI capabilities for just $5.58M. Their open-source approach makes frontier AI accessible to all.
This particularly impacts customer service, where DeepSeek’s cost-effective performance in coding and math tasks enables widespread deployment of specialized AI agents.
DeepSeek’s success shows that clever algorithms matter more than raw computing power, suggesting a future where AI advancement depends on innovation rather than resources. This shifts the competitive landscape from who has the most hardware to who can innovate most efficiently.
If you want access to the latest AI models for customer service, talk to us at Kommunicate!
Manab is the Head of Go-To-Market (GTM) at Kommunicate, with over 12 years of professional experience. He collaborates closely with the engineering, sales, and marketing teams to deliver and position Kommunicate’s AI solutions effectively in the market.
Prior to joining Kommunicate, he worked at Cvent, an enterprise event management software company, and Entropik, an emotion AI company that helps brands understand and interpret consumer emotions.




