Updated on April 4, 2025

How do you reply to a comment like, “I just started learning guitar.”
There are a lot of paths an AI model can take to get a reply. For example, Gemini replies like this:
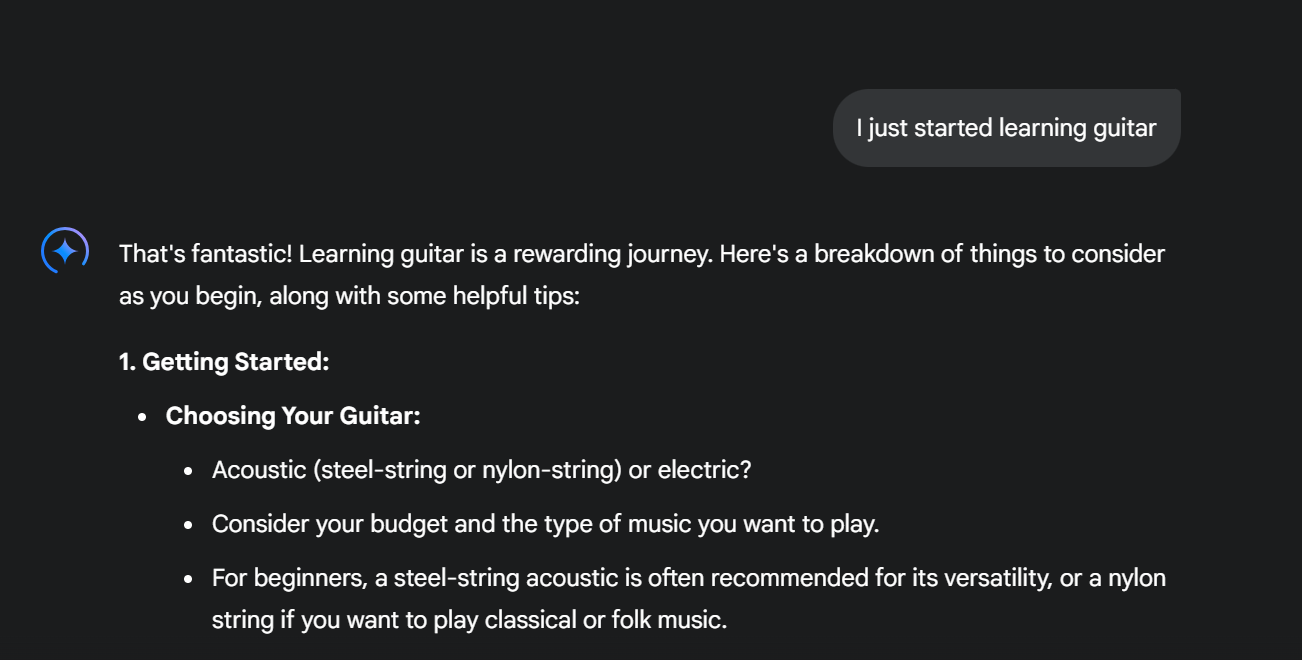
Gemini can use this standard remark and turn it into an actionable conversation in which you learn how to do new things. This is an impressive feat, considering how primitive chatbots were just a few years earlier.
Conversations are free-flowing and need nuance. Language models must adapt to this fluid structure and understand when users want to change topics and switch contexts.
In 2022, chatbots were used to dealing with one-track conversations with little capability to have fluid conversations. They were also not good at working with language to have sensible and interesting conversations with humans.
This is where LaMDA comes in. It’s a series of conversational AI models optimized for human interaction. The research here forms the backbone of multiple new LLMs, including the latest Gemini 2.5 Exp launch from Google.
This article will investigate the LaMDA architecture and explain how it navigates human-like conversations. We’ll cover:
- What is the Structure of LaMDA? A Primer on Transformers
- How was LaMDA Trained?
- How Does LaMDA Maintain Context in Conversations?
- What are the Strengths and Limitations of LaMDA’s architecture?
What is the Structure of LaMDA? A Primer on Transformers
LamDA, or Language Model for Dialog Applications, is a series of conversational chatbots with up to 137B parameters and trained on up to 1.56T words. These models were launched after GPT-3 and improved the conversation capability and the groundedness of the answers.
The LaMDA series of models uses a decoder-only transformer. This is an evolution of the encoder-decoder transformers model introduced by Google in 2017.
How Do Transformers Work?
Let’s take an introductory sentence like “I sat on a mat.”
A transformer model pays attention to each word in the sentence and tries to find the most important related words. So, if a transformer were to pay attention to the word “sat,” it would try to find the word that relates to it the most, so here, “I” and “mat” would be connected with sat.
Now, whenever you input a query into a chatbot, it forms three vectors (numerical values that are used for calculations).
- Query – This is the original question
- Key – This measures the entire content of the query
- Value – This measures the information that the query needs
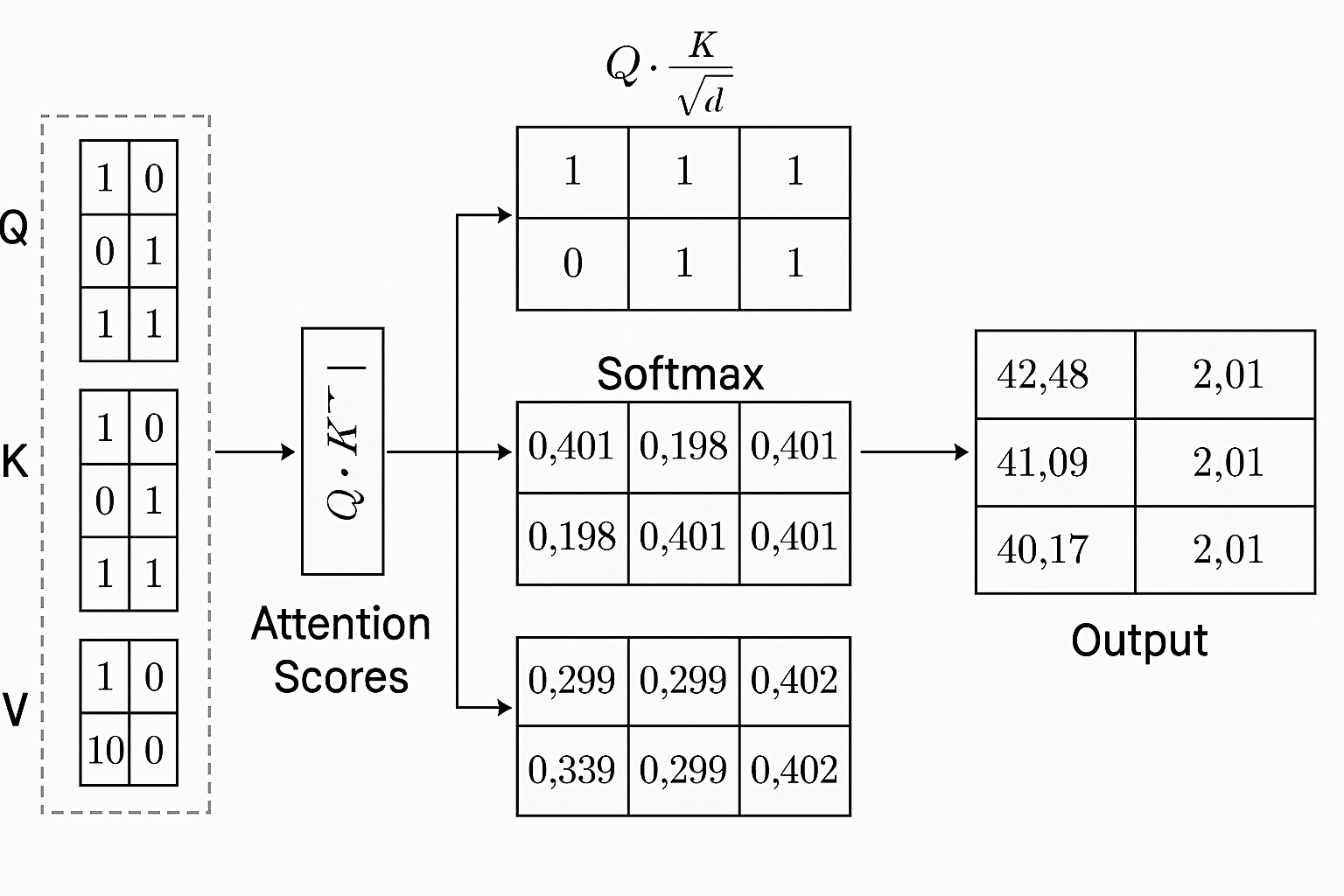
So, each word or token within the query is measured against the keys of all other words or tokens within the key. Based on similarity, it knows how much attention it needs to pay to each word in the query.
These scores are then turned into weights for the model using softmax (this makes it into a probability distribution that adds up to 1). All these tokens aggregate information from other tokens based on their weight.
Taking it step-by-step, this looks like:
- Input – Each word in your query is represented as vectors of size d, and a batch of these is sent to the neural network.
- Creating Keys, Queries, and Values – These input tokens are then multiplied with the neural network weights to make the query, key, and value vectors.
- Calculating Attention – For every pair of tokens in a sequence, we calculate how much attention one token should pay to another. If you do this for each pair, you get a matrix of scores.
- Scaling and Softmax – To normalize, each of the attention scores is divided by the square root of the size of the vector. Then, the softmax algorithm is applied to all matrix members to create a probability distribution.
- Final Output – The output vectors are calculated. Each output vector is the weighted sum of all the value vectors, with the weights being the attention score from a specific word’s perspective.
Once transformers have generated this output, it is passed onto a linear layer. The linear layer contains the entire vocabulary of the LLM. So, when the output is multiplied by the weights of the vocabulary-based linear layer, you get another matrix.
Applying softmax over this new matrix gives you the probability of the next token. Now, multiple algorithms choose which token will be finally selected.
For example, LaMDA’s decoder transformer model predicts multiple next-token options by sampling its vocabulary. Then, it calculates the likelihood of one of these predictions being correct, ranks them, and outputs the answer.
This is similar to how Gemini gives you the final answer in our first example. Now, let’s talk about how LaMDA was trained.
How was LaMDA Trained?
Remember that when GPT 3 was released, LLMs weren’t very reliable. Even now, the current non-reasoning SOTA model (ChatGPT 4.5) hallucinates 37% of the time.
However, even this advance came after much research, and the first steps were laid out in the LaMDA training process. So, let’s understand how the LaMDA set of models was trained.

Pre-Training
Most LLMs are trained on large volumes of unlabeled text to create a representation of the world within itself. It’s kind of like how a child learns, so, basically –
- The LLM reads a lot of text
- Using the texts, it starts forming relationships between different words
- Using these connections, the LLMs understand the meaning of the words and can predict the next word in a sequence
During this process, the transformer network is run repeatedly and told to predict the next token in different examples. One of the words is masked, the model is said to expect, and the weights of the e are updated to maximize the correct predictions. This is unsupervised learning (i.e., no human intervention is required), and the model comes out with an understanding of the world.
LaMDA was pre-trained with:

- 1.56 trillion words from public dialogue data and web documents.
- This included:
- 50% of conversations from public forums
- 12.5% Common Crawl Data
- 12.5% code documentation
- 12.5% English Wikipedia
- 6.25% English web documents
- 6.25% Non-English web documents
This massive amount of data was tokenized with the SentencePiece library. For the most significant 137B model, the neural network was 64 layers deep. To generate the next token, the model was tuned to develop 16 predictions and choose the most likely to be the next.
Pre-training taught LaMDA to fill in the blanks, but our latest models can have full-fledged conversations with us. To get there, the model was fine-tuned further.
Fine-Tuning
Pre-training only teaches the model to predict the next token, But this isn’t enough.
For example, The answer to “I have started learning guitar.” might be the following:
- “That’s great!”
- “Guitars are excellent instruments.”
- “Guitar comes from the early 17th-century Spanish word Guiterra.”
These are all valid responses. These responses must become more interesting, sensible, and specific. This is why the LaMDA set of models was trained to become more competitive in producing SSI (Sensitive, Specific, and Interesting) answers.
This happened in two steps:
1. Quality Fine-Tuning
The model was trained to rank its responses based on the SSI metric. So, each answer from the model had a specific score.
Now, answers that didn’t meet the quality threshold were removed. These chosen answers were re-ranked. These answers were then used to fine-tune the LLM to generate safe, sensible, and interesting answers.
2. Grounded Fine-Tuning
The second problem for the Goole researchers was the high hallucination rates of their language models. The model was allowed to use a toolset: one information retrieval algorithm, a calculator, and a translator.
Here, the model was taught to ask specific questions to the toolset. For example, if someone asked LaMDA about the age of Roger Federer, it would ask the toolset for information. When the toolset gave the verified answer, the model would generate its answer based on the input from the toolset.
The pre-training and fine-tuning processes helped LaMDA become the language model it is. It was able to give precise answers to questions and maintain conversations.
The following section will discuss how this architecture helped LaMDA have multi-turn conversations in more detail.
How Does LaMDA Maintain Context in Conversations?
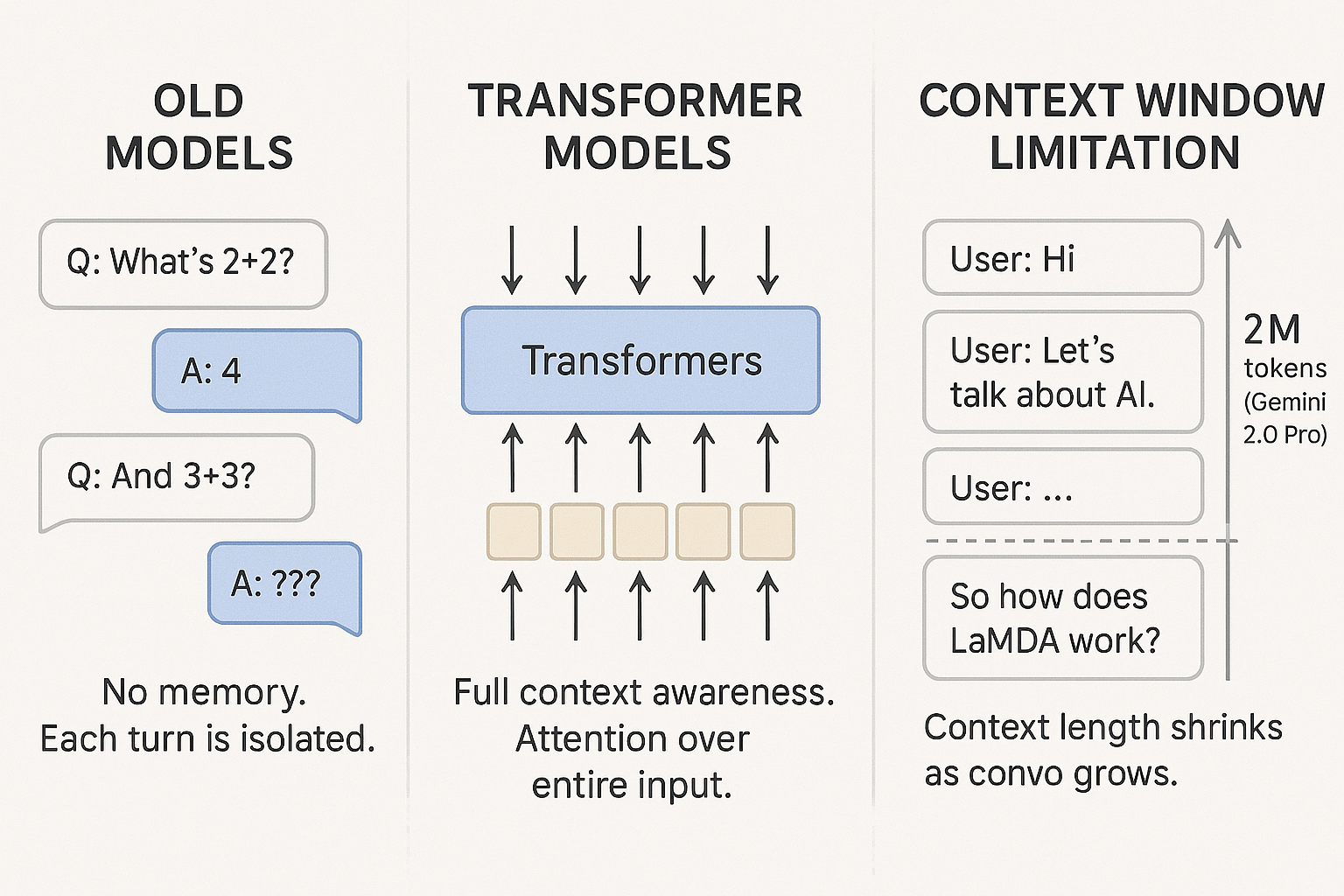
One of the limitations of older AI models was the lack of parallelization. So, in a conversation, the AI model will immediately forget the earlier message.
This was fine for very basic QnAs but not for multi-turn conversations.
Transformers solve this by paying attention to the entire token sequence in parallel. So your LLM can understand the whole context of the input.
As the conversation progresses, the entire discussion is fed back to the LLM (This is why most LLMs have a finite conversation length). And LaMDA demonstrates this very well. Because as you have longer and longer conversations, the effective context length available to the LLM shrinks.
Currently, the model with the largest known context length is Gemini 2.0 Pro, with 2 million context tokens. Since the Gemini series of LLMs evolved out of LaMDA, you can see how foundation these conversational AIs have been for the development of LLMs in general.
However, given how much LLMs have evolved in the past two years, it is interesting to understand the strengths and limitations of the LaMDA model.

What are the Strengths and Limitations of LaMDA’s architecture?
We’ve created a quick overview of the strengths and limitations of the LaMDA architecture:
| Strengths | Limitations |
| Strong contextual understanding and ability to maintain coherent dialogue | Only focused on open-ended conversational AI |
| Excels at generating human-like and interesting responses | Has a smaller knowledge base compared to more general models |
| Capacity to handle open-ended conversations and adapt to topic shifts | Susceptible to biases present in training data, raising ethical concerns |
| Strengths in specificity, factuality (enhanced by retrieval augmentation), interestingness, and sensibleness | Interpretability and explainability of decision-making processes can be limited |
| Adaptable to individual user preferences | Bad at factual accuracy |
| Shows promise in understanding and emulating empathy and sentiment | Not practical for task-based projects |
While LaMDA is a performant model, it lacks some of the modern models’ strengths. It was biased and not great at completing tasks. While it could have good conversations, it couldn’t solve the problems that the current LLMs can.
However, as a foundational model, LaMDA is still very interesting, and its AI architecture significantly influences the current SOTA models.
Conclusion
LaMDA was a set of conversational AI models from Google that were trained to have specific and engaging conversations. The primary things that LaMDA optimized for are:
- Sophisticated Training Methodology: Through its innovative two-step fine-tuning process – Quality Fine-Tuning and Grounded Fine-Tuning – LaMDA significantly improved response quality and reduced hallucinations.
- Nuanced Response Generation: The model moved beyond mere token prediction, focusing on generating responses that are sensitive, specific, and interesting (SSI).
Historical Significance
While LaMDA is not the most advanced model today, its research laid crucial groundwork for subsequent conversational AI developments. The model served as a bridge between primitive chatbots and modern large language models like Gemini and showed how transformer-based models can be used to have conversations at scale.
Some Thoughts
At Kommunicate, we’re passionate about solving problems with conversational AI. We’ve been building new features that address your customer service challenges around live chat, email and voice (coming soon).
Talk to us if you want to power your customer service conversations with the latest SOTA models!

Adarsh Kumar is the CTO & Co-Founder at Kommunicate. As a seasoned technologist, he brings over 14 years of experience in software development, artificial intelligence, and machine learning to his role. His expertise in building scalable and robust tech solutions has been instrumental in the company’s growth and success.




