Updated on February 12, 2025

Google’s Vertex AI is a Google Cloud-based platform that entrepreneurs, developers, and AI researchers can use to manage their AI projects. We have discussed the architecture of the entire Vertex AI ecosystem at length in a previous article, “Google Vertex AI: Accelerating AI Development & More.”
This article will discuss managed ML datasets in Vertex AI and how to use them to create generative AI applications. The topics we’ll cover here are:
2. How to Prepare Managed Datasets?
2.1. Image-Based Datasets
2.2. Tabular Datasets
2.3. Text Datasets
2.4. Video Datasets
3. How to Create a Managed Dataset?
4. Conclusion
What Are Managed Datasets?
Managed Datasets are datasets that work within the Vertex AI framework. You need them for AutoML training (and Gemini training) but not for your custom models.
However, managing databases reduces your workload within the Vertex ecosystem by providing multiple functionalities. The benefits of managed databases are:
1. You can manage your datasets from a centralized location.
2. You can easily create labels and multiple annotation sets.
3. You can create tasks for human labeling.
4. You can track the lineage of this database based on AI models to iterate and train.
5. You can compare AI model performance by training multiple models using the same dataset.
6. You can generate statistics data,
7. Vertex allows you to split your datasets into training, test, and validation data.
These features allow you to run your AI project end-to-end natively on Vertex AI with any dataset you want. You can also use the datasets provided by Google to train your models and check their performance.
Reduce response time, enhance support workflows, and improve customer satisfaction with AI-driven email ticketing from Kommunicate!However, the database you get access to will depend on the server location for the dataset. Since the speed of training and iteration depends on your physical distance from the server you choose, it is recommended that you select the closest location to the models and training datasets you need for your projects.
Now, let’s talk about creating datasets.
How Do You Prepare Datasets for Vertex AI?
Managed Datasets for Vertex AI can be created using Google Cloud Platform (GCP) or Google Vertex APIs. Your process will differ based on the data type you’re working with and the operations you want to perform.
For each data set you import, you need a structured JSON or CSV file that puts your data in a structure and allows annotation.
Preparing Image Datasets
Image Datasets for Classification
Classification tasks are tasks that automatically label images and identify features. For example, a classification task might be to find the type of flower pictured in a photograph. Let’s talk about the data you need to train such a model.
Supported Image Formats
You can train both single-label and multi-label classification models using Vertex. Both types of models accept the following types of images as inputs-
1. PNG
2. JPEG
3. GIF
4. BMP
5. ICO
Output images will follow the same file formats, but if required, these models can also be trained to output TIFF and WEBP files.
Note: Also, remember that your files need to be Base64 encoded.
Preparing the Data
Now, we will prepare the image for single-label classification. You need to follow a JSON format that looks like this:
{
"imageGcsUri": "gs://bucket/filename.ext",
"classificationAnnotation": {
"displayName": "LABEL",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "training/test/validation"
}
}Here,
1. imageGCsUrl – Specifies the location of the image
2. annotationResourceLabels – This is a pair of strings showcasing key-value pairs. This is used to annotate your input data. Only one is reserved by the system: “aiplatform.googleapis.com/annotation_set_name”:”displayName.”
3. dataitemResourceLabels – Another pair of strings with key-value pairs. This is used to specify the metadata of the image you’re uploading. The system reserves one pair: “aiplatform.googleapis.com/ml_use”: “training/test/validation”
For illustration, if we had three images in a gs://bucket for Kommunicate, we might generate a JSON format like:
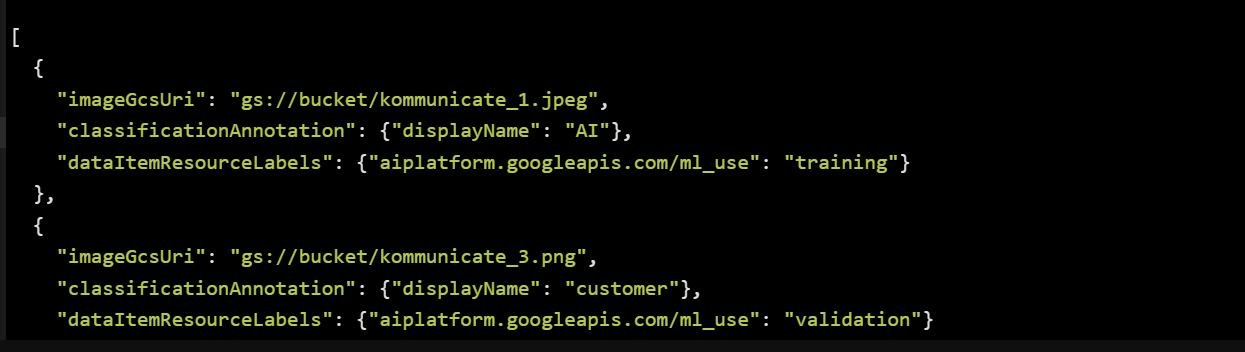
Further, you can use the label_type custom key-value pair to classify multiple labels you add to images.
Guidelines
Now, there are some guidelines you need to follow for these datasets:
1. Vertex is optimized for real-world images.
2. Your training data determines the output, so the images should be close. For example, if you want to analyze low-quality, blurry photos, you must train your model on similar images.
3. Vertex AI has limited prediction capabilities, so if a human can’t classify an image within 1-2 seconds, Vertex AI can’t either.
4. It’s recommended that you train on at least 1000 images.
5. It’s better to keep images with the most frequently appearing label at a volume of 100x compared to the photos labeled with the least frequent label.
6. A None_of_the_above classifier can help the model function better.
Another popular business use case for image-based ML models is object detection, so let’s discuss that next.
Image Datasets for Object Detection
In object detection models, the model tries to find a specific object within a photograph. This is useful for finding particular patterns or objects in an image. For example- You can use it to find brand logos in a street photography dataset.
Let’s talk about preparing your dataset for these tasks.
Supported Image Formats:
Vertex AI supports the following image formats for object detection and identification:
- PNG
- JPEG
- GIF
- BMP
- ICO
Output Formats:
Trained models typically output images in the same format as the training data. However, Vertex AI can also output:
- TIFF
- WEBP
Preparing Images for Object Identification:
Vertex AI uses a specific JSON format for object identification tasks. Here’s an example:
{
"imageGcsUri": "gs://bucket/filename.ext", # Location of the image
"objectAnnotations": [
{
"boundingBox": {
"normalizedVertices": [
{ "x": 0.1, "y": 0.2 },
{ "x": 0.3, "y": 0.2 },
{ "x": 0.3, "y": 0.4 },
{ "x": 0.1, "y": 0.4 }
]
},
"displayName": "LABEL", # Label associated with the object
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName", # Annotation set name
"env": "prod" # Optional custom key-value pair (e.g., environment)
}
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "training/test/validation" # Intended use of the data item
}
}In this example, the JSON fields mean:
- imageGcsUri: This specifies the Google Cloud Storage URI of the image file
- objectAnnotations: This array contains objects representing detected objects in the image
- boundingBox: This object defines the bounding box around the object
- normalizedVertices: This array specifies the coordinates of the bounding box vertices in normalized coordinates (0 to 1)
- displayName: This key holds the label associated with the detected object
- annotationResourceLabels: This object provides additional metadata about the annotation
- aiplatform.googleapis.com/annotation_set_name: This key references an existing annotation set where relevant annotations are grouped. Replace “displayName” with the actual set name
- env (optional): Add custom key-value pairs here for additional information (e.g., environment)
- aiplatform.googleapis.com/annotation_set_name: This key references an existing annotation set where relevant annotations are grouped. Replace “displayName” with the actual set name
- boundingBox: This object defines the bounding box around the object
- dataItemResourceLabels: This object provides metadata about the data item itself
- aiplatform.googleapis.com/ml_use: This key specifies the intended use of the data item (“training,” “test,” “validation”)
For example, for an image in our Google Cloud bucket called Kommunicate_1.jpeg, we’d write a JSON:
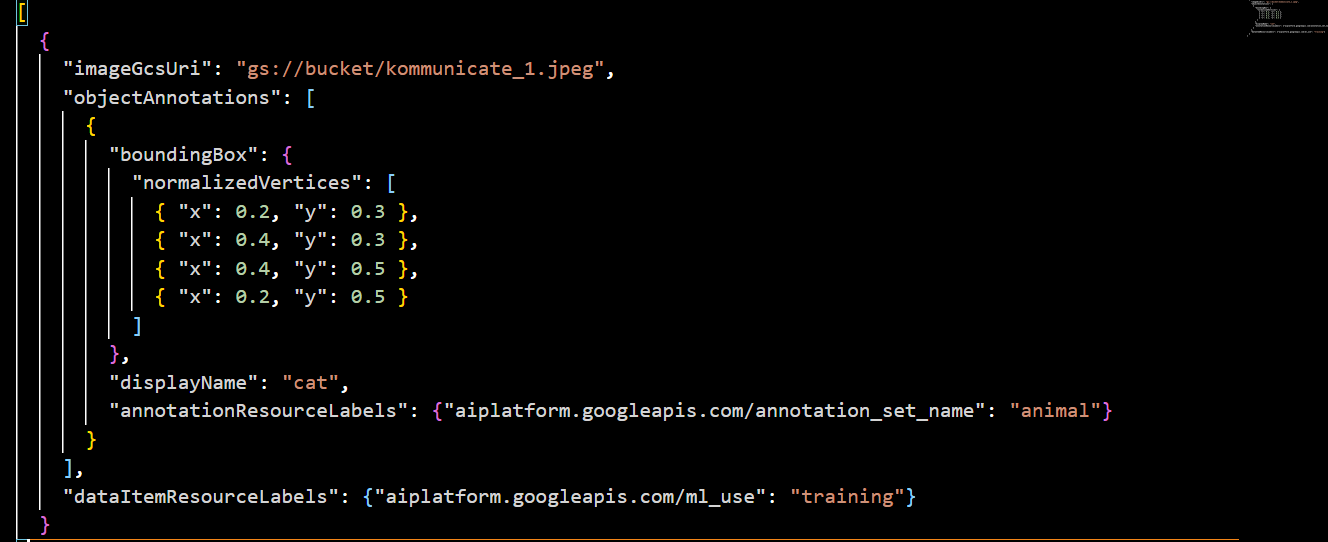
Dataset Guidelines
Image Size:
- Optimal Range: Aim for image sizes between 512×512 and 1024×1024 pixels.
- Scaling: 1024×1024 is the suggested maximum. If images are significantly larger, consider scaling them down while maintaining the aspect ratio.
Bounding Box Size:
- Accuracy: Ensure bounding boxes are tightly fitted around objects.
- Avoid Overlap: Minimize overlap between bounding boxes.
- Size Variation: Include bounding boxes of various sizes.
- Normalization: Use normalized coordinates (0 to 1) for bounding boxes.
Additional Considerations:
- Aspect Ratio: Maintain the original aspect ratio of images.
- Data Augmentation: Experiment with techniques like cropping, padding, and resizing.
- Hardware Limitations: Consider your hardware resources when setting image and bounding box sizes.
Dataset Quality and Diversity:
- Image Quality: Use high-quality images with diverse backgrounds, lighting conditions, and object sizes.
- Label Accuracy: Ensure accurate and consistent labeling.
- Data Volume: Aim for a sufficiently large dataset.
- Data Balance: Maintain a balanced dataset.
- Annotation Consistency: Ensure consistency in annotation types and attributes.
Annotation Set Management:
- Create Sets: Organize annotations into sets based on object categories or attributes.
- Assign Annotations: Associate annotations with appropriate sets.
Metadata:
- Include Metadata: Add relevant metadata like object types, attributes, or timestamps.
Data Format:
- JSON Format: Use the provided JSON format for object detection and classification tasks.
- Schema Definition: Define an explicit schema for your dataset.
Once you’ve prepared the datasets in the specified format for both image-based tasks, you can start using them in your tasks. Next up are tabular datasets.
Preparing Tabular Datasets
Tabular Datasets for Classification and Regression
Classification tasks for this context are tasks that predict the categorical outcome. So, if you want to predict if a customer will churn, you can use these models.
Regression tasks are used to predict continuous numerical data, so if you want to correlate the price of a house with data.
Important Note: For Tabular data, Vertex randomly splits 80% of your data into training, 10% for validation, and 10% for test cases. If you want a manual split or want to map it chronologically, you’ll need to add a separate split column.
Outside of this, your dataset must have the following.
Guidelines for Dataset
- Maximum Size: The dataset must be 100 GB or smaller.
- Number of Columns:
– Minimum: 2 columns (including target and at least one feature)
– Maximum: 1,000 columns (including features and non-features) - Target Column:
– Specify a Target column that Vertex AI can use to associate the training data with the desired result.
– No Null Values: The target column cannot contain missing values.
- You can add two data types: Categorical or Numerical.
- Categorical:
- Minimum two distinct values
- Maximum 500 distinct values
- Numerical: No restrictions
- Categorical:
- Column Names:
Allowed Characters: Alphanumeric characters and underscore (_). However, the column name can’t start with (_). - Number of Rows:
– Minimum: 1,000 rows
– Maximum: 100,000,000 rows
- Wide Data Format is Preferred: Each row represents one training data item.
- Unless you add specific Weights to your data, all your data will be considered equal. If you want to emphasize a particular subset, assign a relatively more significant number from the range [0,10000] in the Weight column.
Data Sources
You can import tabular data from BigQuery or CSV:
- For BigQuery, you will need a location ID following the format: bq://<project_id>.<dataset_id>.<table_id>
- Each file should be under 10GB for CSV, but you can upload multiple files if the total is less than 100 GB.
Additionally, tabular datasets are also used for forecasting tasks. Let’s move on to them.
Tabular Datasets for Forecasting
Forecasting tasks try to predict future numerical values given historical data. These tasks have a mandatory time series component.
Important Note: As with classification and regression tabular data, your data will be split randomly into training, validation, and test subsets. Depending on your training requirements, you can split this manually or chronologically.
The basic guidelines for the data you need here are as follows.
Guidelines for Dataset
- Dataset size: Maximum 100 GB.
- Number of columns: Minimum 3 (target, time, time series ID), maximum 100. Consider using more than 3 for better performance.
- Target column: Required. You can’t add null values.
- Time column: Required. You need to add a value for each row, and a consistent periodicity is recommended for data granularity.
- Time series identifier column: Add a value for every row to identify which time series an observation belongs to.
- Column names: Use alphanumeric characters and underscores (_); you cannot begin with an underscore.
- Number of rows: Minimum 1,000, maximum 100,000,000. Consider using more than 1,000 rows for better performance.
- Data format: Use a narrow (long) data format, where each row represents a specific time point for a time series ID and its data.
- Interval between rows: Ensure consistent intervals between rows for consistent data granularity.
- Time series length: Maximum 3,000 time steps per time series.
Data Sources
You can import tabular data from BigQuery or CSV.
- For BigQuery, you will need a location ID following the format: bq://<project_id>.<dataset_id>.<table_id>
- Each file should be under 10GB for CSV, but you can upload multiple files if the total is less than 100 GB.
If you want to work with text-based tasks like sentiment analysis or NLP, move on to the next section.
Preparing Text Datasets
You can use the Gemini AI models within Vertex to work with Text Datasets. AutoML for text extraction, classification, and entity recognition is set to be depreciated starting September 15th, 2024.
Now, let’s take a look at preparing datasets for various tasks.
Text Classification Models
Classification models try to sort documents into different categories. This can be used to sort books into genres, sort different research papers into topics, etc. Let’s talk about the specific data requirements.
Data Guidelines
- Minimum Documents: 20
- Maximum Documents: 1,000,000
- Unique Labels: Minimum 2, maximum 5000
- Documents per Label: At least ten documents per label
- Data Format: Inline or reference TXT files in Cloud Storage buckets
Best Practices:
- Data Variation: Use diverse training data with different lengths, authors, wording, and styles.
- Human Categorizability: Ensure documents can be easily categorized by humans.
- Sufficient Examples: Provide as many training documents per label as possible.
- Label Balance: Aim for 100 times more documents for the most common label than the least standard label.
- Out-of-Domain Label: Consider including a “None_of_the_above” label for documents that don’t fit defined labels.
- Filtering: Filter out documents that don’t match your labels to avoid skewing predictions.
Multi-Label Classification:
- Multiple Labels: Documents can have one or more labels.
- Data Requirements: Follow the same guidelines for single-label classification.
To prepare your dataset, follow the instructions given in this .yaml file.
An example of the JSON schema will be as follows:
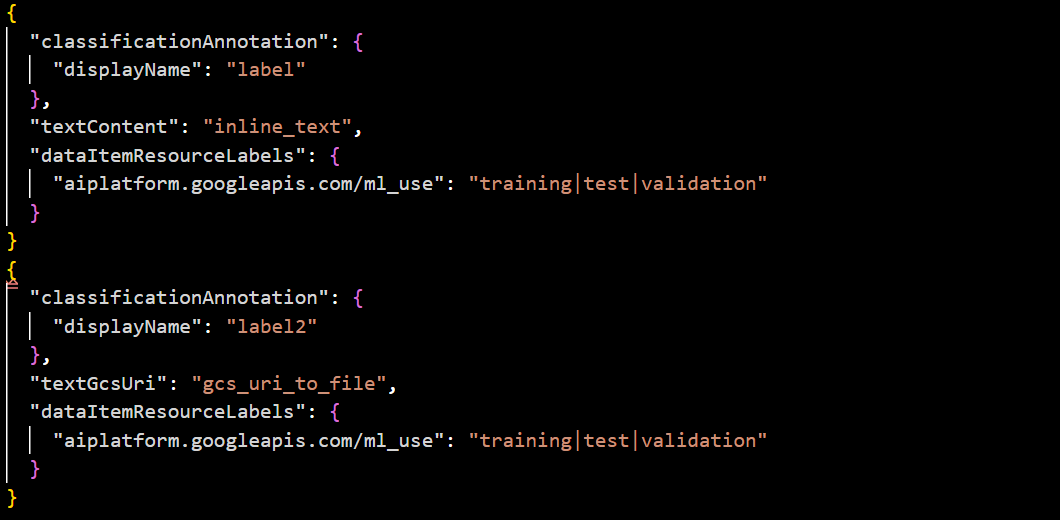
You can use the texts for classification tasks once you’ve prepared your dataset in this format. We’ll try extracting some features from the text for the next set of tasks.
Text Entity Extraction Models
Entity Extraction models are trained to recognize and pull specific entities from the text. For example, you can use this for lead collection and finding a prospect’s name from a chat conversation.
Here are the data requirements.
Data Guidelines
- Minimum Documents: 50
- Maximum Documents: 100,000
- Unique Labels: Minimum 1, maximum 100
- Label Length: Between 2 and 30 characters
- Annotations per Label: At least 200 occurrences of each label
- Annotation Placement: Consider spatial position for structured documents (e.g., invoices, contracts).
Data Format:
- JSON Lines: Include annotations directly in JSON Lines files.
- Cloud Storage: Reference TXT files in Cloud Storage buckets for documents.
Best Practices:
- Annotate All Occurrences: Annotate every instance of entities you want to extract.
- Data Variation: Use diverse training data with different lengths, authors, wording, and styles.
- These models can’t do entity extraction where humans are unable to. So, anything humans can’t categorize can’t be classified through the models.
Additional Considerations:
- Structured Documents: A structured document will let you use the position of the entities for better extraction.
- Data Quality: It’s highly recommended that you should have high-quality annotations and clean data.
- Label Consistency: Maintain consistent labeling practices across your dataset.
Schema
- For Single-Label Classification: Follow this .yaml.
- For Multi-Label Classification: Follow this .yaml.
Prioritizing JSON files is better because AutoML for text-based tasks will be discontinued by September 2024. Gemini will replace it, allowing only JSON files for task implementation
Text Sentiment Analysis Models
Sentiment analysis tasks try to examine text to understand the sentiment behind them. This is very important for customer service chatbots, where sentiment analysis can help businesses understand how customers feel about their chatbots.
The data requirements are:
Data Requirements:
- Minimum Documents: 10
- Maximum Documents: 100,000
- Sentiment Values: Your sentiment values should be integers from 0 to a chosen maximum (For example, you could use the range [0,1,2] where 0 is negative, 1 is neutral, and 2 is positive)
- Documents per Sentiment: Add at least ten documents for each sentiment value
- Sentiment Score Consistency: Your sentiments must be consecutive integers starting from 0.
- Data Format: You can add inline text or use your Google Cloud Storage reference text files.
Best Practices:
- Documents per Sentiment: Aim for at least 100 documents per sentiment value.
- Balanced Dataset: To avoid bias, use a balanced number of documents for each sentiment score.
- Data Variation: Include diverse text data with different lengths, authors, and styles.
- Human Categorizability: If a human being cannot identify the sentiment in the document you give for prediction, the machine learning algorithm won’t be able to do either.
Schema
- For JSON Files – Use this schema.
- For CSV Files – Use the following columns. The [ml_use] column is optional
[ml_use],gcs_file_uri|"inline_text",sentiment,sentimentMaxFor example, if we want to import two types of text (one inline and one .txt document) through a JSON file, we use the following format:
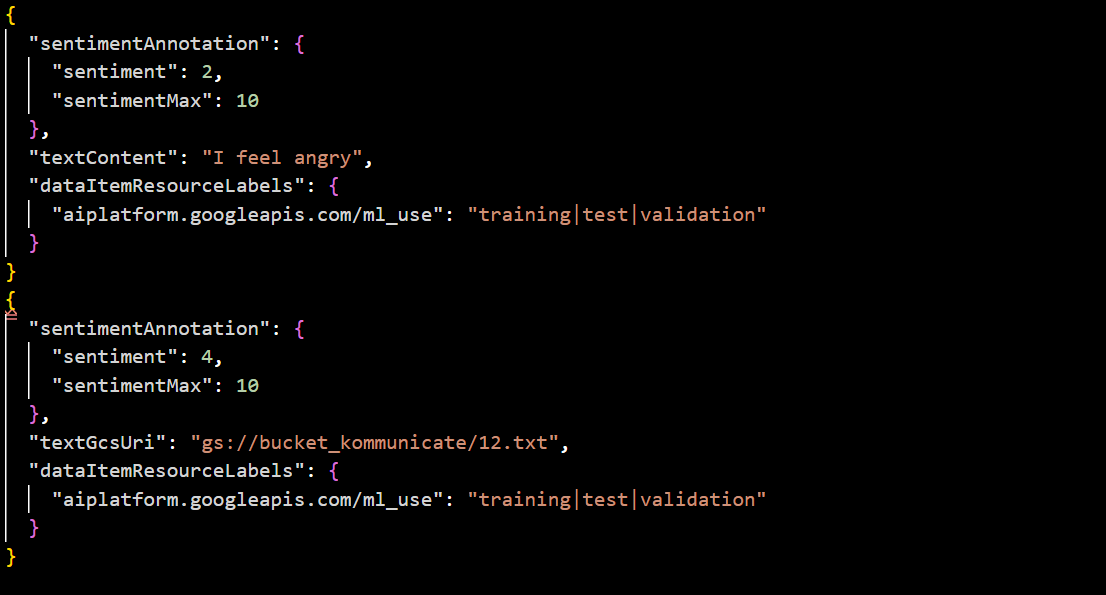
Important Note: Support for Text AutoML models will be depreciated starting September 2025, after which only Gemini models will be available for these tasks. CSV data is not recommended since Gemini models only use structured JSON data.
Preparing Video Datasets
Video Data for Action Recognition
Action recognition machine learning tasks try to identify specific human actions in a video. So, these algorithms identify and categorize human behavior in a process.
This might be important for security initiatives in banking.
Data Formats:
- Supported Formats: .MOV, .MPEG4, .MP4, .AVI
- Recommended Formats: It’s preferable to use MPEG4 or .MP4 for browser compatibility.
File Size:
- Maximum: 50 GB (up to 3 hours).
- Malformed Timestamps: Avoid files with malformed or empty timestamps.
Label Limit:
- Maximum Labels: 1,000 per dataset.
Action Recognition:
- Label All Actions: Use the VAR labeling console to label all actions in a video.
Best Practices:
- Data Relevance: Use training data similar to your target data (e.g., blurry videos for security camera use cases).
- Human Categorizability: Ensure humans can assign the labels within 1-2 seconds.
- Label Balance: Aim for 100 times more videos for the most common label than the least common one.
- Action Recognition: Use at least 100 training video frames per label and consider image quality limitations for large resolutions.
Schema
JSON – Use the following JSONL file for your schema.
For example:
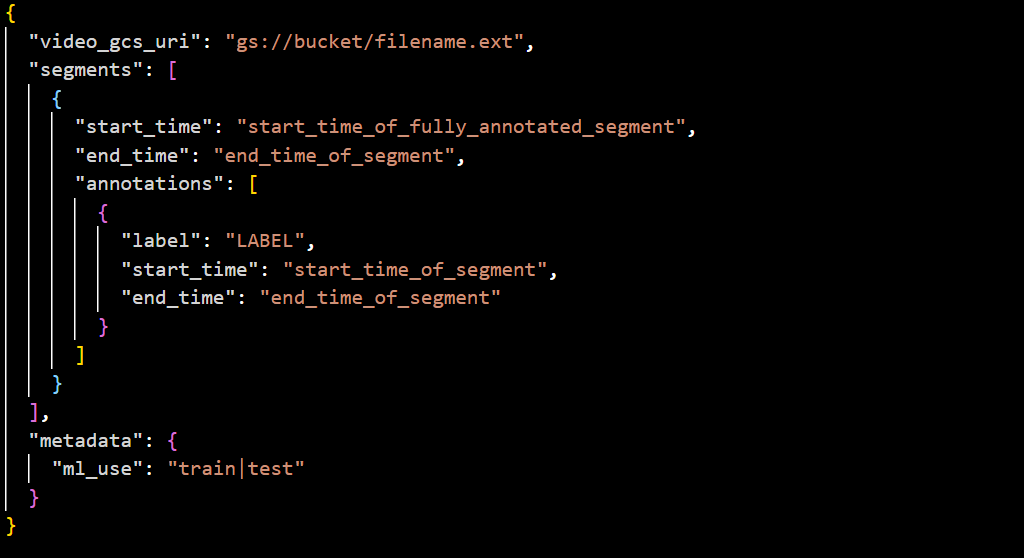
CSV – Your CSV files need to follow the following format.
VIDEO_URI, TIME_SEGMENT_START, TIME_SEGMENT_END, LABEL, ANNOTATION_SEGMENT_START, ANNOTATION_SEGMENT_ENDVideo Data for Classification
Classification tasks for videos try to label videos based on the training data. For granularity, it is recommended that you create a global label and one label for each frame of the video.
Data Formats:
- Supported Formats: .MOV, .MPEG4, .MP4, .AVI
- Recommended Formats: MPEG4 or .MP4 for browser compatibility
File Size:
- Maximum: 50 GB (up to 3 hours)
- Malformed Timestamps: Avoid files with malformed or empty timestamps.
Label Limit:
- Maximum Labels: 1,000 per dataset
ML_USE Labels:
- Optional: Assign “ML_USE” labels for training/test splits.
Video Classification:
- Adding Classes: Add at least two different classes (e.g., “news” and “MTV”).
- Out-of-Domain Label: Consider “None_of_the_above” for uncategorized videos.
Best Practices:
- Data Relevance: Use training data similar to your target data (e.g., blurry videos for security camera use cases).
- Human Categorizability: Ensure humans can assign labels within 1-2 seconds.
- Label Balance: Aim for 100 times more videos for the most common label than the least common one.
- Training Videos: Use at least 100 training videos per label (50 for advanced models).
- Multiple Labels: You need more examples for each label when you use multiple labels in a video, and interpretation might be challenging.
Schema
JSON – Follow the following schema.
For Example:
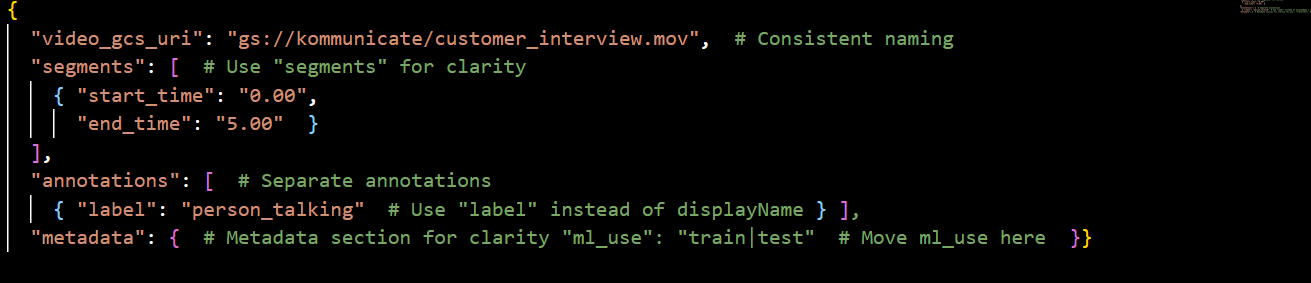
CSV – For CSV, use the following format:
[ML_USE,]VIDEO_URI,LABEL,START,ENDVideo Data for Object Tracking
Object tracking lets you track an object through video frames. These tasks allow you to find and track a specific object in your video.
Data Formats:
- Supported Formats: .MOV, .MPEG4, .MP4, .AVI
- Recommended Formats: MPEG4 or .MP4 for browser compatibility
File Size:
- Maximum: 50 GB (up to 3 hours)
- Malformed Timestamps: Avoid files with malformed or empty timestamps.
Label Limits:
- Maximum Labels per Dataset: 1,000
- Maximum Labeled Frames: 150,000
- Maximum Bounding Boxes: 1,000,000
- Minimum Labels per Annotation Set: 1,000
ML_USE Labels:
- Optional: Assign “ML_USE” labels for training/test splits.
Best Practices:
- Data Relevance: Use training data similar to your target data (e.g., blurry videos for security camera use cases).
- Human Categorizability: Ensure humans can assign labels within 1-2 seconds.
- Label Balance: Aim for 100 times more videos for the most common label than the least common one.
- Bounding Box Size: Minimum bounding box size of 10 px by 10 px.
- Label Frequency: Each unique label should be present in at least three distinct video frames with at least ten annotations.
- Video Resolution: Consider image quality limitations for large resolutions (over 1024 pixels by 1024 pixels).
Schema
JSONL: You can use the following schema file.
For example:
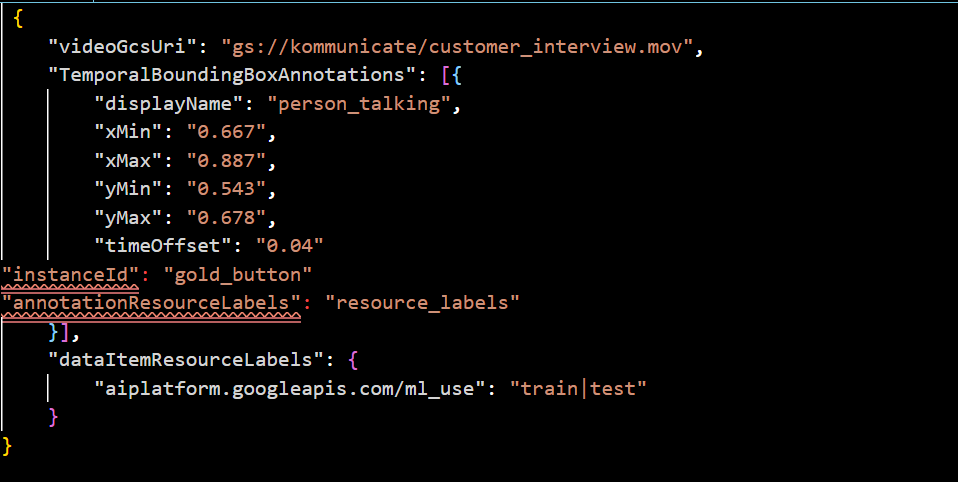
CSV: For CSV, use the following format:
[ML_USE,] VIDEO_URI, LABEL, [INSTANCE_ID], TIME_OFFSET, BOUNDING_BOXHow to Create Managed Datasets?
This video outlines how you can use managed datasets in Vertex AI:
For creating datasets in Vertex AI, follow the following steps:
1. In the Google Cloud Console, and in the Vertex AI section go to the Datasets page.
2. Click on Create.
3. Select the tab based on your data – Image/Text/Video/Tabular.
4. Select the task.
5. Select a Region which has the resource that you want to use.
6. Click Create to create an empty dataset and then go to Data Import.
7. Choose where you want to import your data from, you can use an import file (the JSON and CSV files you’ve created) from your computer, select an import file from your cloud storage, or select all the files from your computer.
8. Click Continue.
This will start the upload process for your data, and create a managed dataset that you can use for your projects.
Conclusion
In this article, we cover the different types of tasks and datasets that you can create in Vertex AI. Remember that these datasets can be used across multiple models for comparisons and specific training processes.
Depending on your goals, you will have to customize your dataset and training data. We hope you will get great results with Google’s Vertex AI models!

Adarsh Kumar is the CTO & Co-Founder at Kommunicate. As a seasoned technologist, he brings over 14 years of experience in software development, artificial intelligence, and machine learning to his role. His expertise in building scalable and robust tech solutions has been instrumental in the company’s growth and success.




